11/09/2023 às 16h46min - Atualizada em 11/09/2023 às 20h08min
NVIDIA Grace Hopper Superchip lidera nos benchmarks de inferência MLPerf
GPUs NVIDIA GH200, H100 e L4 e os módulos Jetson Orin apresentam desempenho superior executando IA em produção, da nuvem até a borda da rede
Isadora Fernandes
https://www.nvidia.com/pt-br/
 Sim
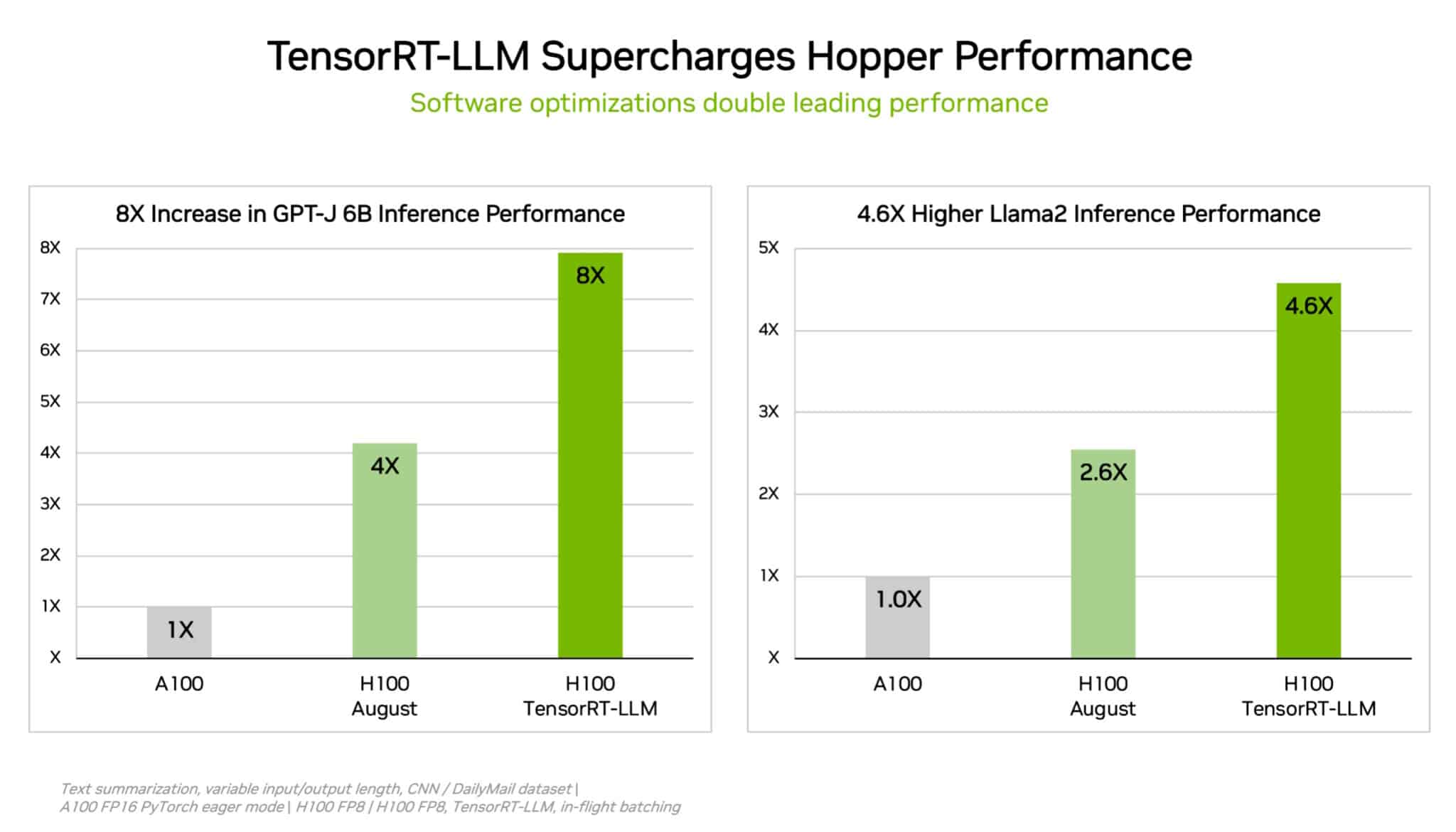
Sim Em sua estreia nos benchmarks da indústria MLPerf, o NVIDIA GH200 Grace Hopper Superchip executou todos os testes de inferência de data center, ampliando o desempenho líder das GPUs NVIDIA H100 Tensor Core. Os resultados gerais mostraram o desempenho e a versatilidade excepcionais da plataforma de IA da NVIDIA, desde a nuvem até a borda da rede. O GH200 conecta uma GPU Hopper com uma CPU Grace em um superchip. A combinação fornece mais memória, largura de banda e capacidade de alternar automaticamente a energia entre a CPU e a GPU para otimizar o desempenho. Separadamente, os sistemas H100 que incluem oito GPUs H100 forneceram o maior rendimento em todos os testes de inferência MLPerf nesta rodada. Grace Hopper Superchips e GPUs H100 lideraram todos os testes de data center do MLPerf, incluindo inferência para visão computacional, reconhecimento de fala e imagens médicas, além dos casos de uso mais exigentes de sistemas de recomendação e dos grandes modelos de linguagem (LLMs) usados em IA generativa. No geral, os resultados dão continuidade ao histórico da NVIDIA de demonstrar liderança de desempenho em treinamento e inferência de IA em todas as rodadas desde o lançamento dos benchmarks MLPerf em 2018. A última rodada do MLPerf incluiu um teste atualizado de sistemas de recomendação, bem como o primeiro benchmark de inferência em GPT-J, um LLM com seis bilhões de parâmetros, uma medida aproximada do tamanho de um modelo de IA. "Estamos extremamente felizes por mais uma vez alcançar resultados notáveis no MLPerf, pois eles enfatizam a performance e versatilidade da plataforma de IA da NVIDIA. Isso contribui significativamente para fortalecer ainda mais nossa posição de liderança neste cenário", comemora Marcio Aguiar, diretor da divisão Enterprise da NVIDIA para América Latina. TensorRT-LLM sobrecarrega GPUs H100 Para eliminar cargas de trabalho complexas de todos os tamanhos, a NVIDIA desenvolveu o TensorRT-LLM, software de IA generativa que otimiza a inferência. A biblioteca de código aberto – que não ficou pronta a tempo para o envio em agosto ao MLPerf – permite que os clientes mais que dupliquem o desempenho de inferência de suas GPUs H100 já adquiridas, sem custo adicional.
Os testes internos da NVIDIA mostram que o uso do TensorRT-LLM em GPUs H100 fornece uma aceleração de desempenho de até 8x em comparação com GPUs da geração anterior executando GPT-J 6B. Os testes também revelam uma redução de 5,3x no custo total de propriedade e uma redução de 5,6x nos custos de energia. O software começou no trabalho da NVIDIA acelerando e otimizando a inferência LLM com empresas líderes, incluindo Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (agora parte do Databricks), OctoML, Tabnine e Together AI. O MosaicML adicionou recursos necessários ao TensorRT-LLM e os integrou ao conjunto de serviços existente. “Tem sido muito fácil”, diz Naveen Rao, vice-presidente de engenharia da Databricks. “O TensorRT-LLM é fácil de usar, repleto de recursos e eficiente”, afiema Rao. “Ele oferece desempenho de última geração para serviços LLM usando GPUs NVIDIA e nos permite repassar a economia de custos aos nossos clientes.” TensorRT-LLM é o exemplo mais recente de inovação contínua na plataforma full-stack AI da NVIDIA. Esses avanços contínuos de software proporcionam aos usuários um desempenho que cresce ao longo do tempo, sem custo adicional, e é versátil nas diversas cargas de trabalho de IA atuais. L4 aumenta a inferência em servidores convencionais Nos benchmarks MLPerf mais recentes, as GPUs NVIDIA L4 executaram toda a gama de cargas de trabalho e proporcionaram excelente desempenho em todas as áreas. Por exemplo, GPUs L4 executadas em placas adaptadoras compactas de 72 W oferecem até 6x mais desempenho do que CPUs classificadas para consumo de energia quase 5x maior. Além disso, as GPUs L4 apresentam mecanismos de mídia dedicados que, em combinação com o software CUDA, fornecem velocidades de até 120x para visão computacional nos testes da NVIDIA. GPUs L4 estão disponíveis no Google Cloud e em muitos integradores de sistemas. Elas atendem clientes em setores que vão desde serviços de internet ao consumidor até descoberta de medicamentos. Aumentos de desempenho no limite Separadamente, a NVIDIA aplicou uma nova tecnologia de compressão de modelo para demonstrar um aumento de desempenho de até 4,7x executando o BERT LLM em uma GPU L4. O resultado foi a chamada divisão aberta do MLPerf, categoria para apresentação de novas capacidades. Espera-se que a técnica seja usada em todas as cargas de trabalho de IA. Pode ser especialmente benéfico ao executar modelos em dispositivos de ponta com tamanho e consumo de energia limitados. Em outro exemplo de liderança em computação de ponta, o sistema em módulo NVIDIA Jetson Orin mostrou aumentos de desempenho de até 84% em comparação com a rodada anterior na detecção de objetos, um caso de uso de visão computacional comum em cenários de IA de ponta e robótica.
O avanço do Jetson Orin veio de um software que aproveita a versão mais recente dos núcleos do chip, como um acelerador de visão programável, uma GPU de arquitetura NVIDIA Ampere e um acelerador dedicado de deep learning. Desempenho versátil, amplo ecossistema Os benchmarks MLPerf são transparentes e objetivos, para que os usuários possam confiar em seus resultados para tomar decisões de compra. Eles cobrem uma ampla variedade de casos de uso e cenários, para que os usuários saibam que podem obter um desempenho confiável e flexível para implantação. Os parceiros inscritos nesta rodada incluíram os provedores de serviços em nuvem Microsoft Azure e Oracle Cloud Infrastructure e os fabricantes de sistemas ASUS, Connect Tech, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, QCT e Supermicro. No geral, o MLPerf é apoiado por mais de 70 organizações, incluindo Alibaba, Arm, Cisco, Google, Universidade de Harvard, Intel, Meta, Microsoft e Universidade de Toronto. Leia o blog técnico para obter mais detalhes sobre como a NVIDIA alcançou os resultados mais recentes. Todo o software usado nos benchmarks da NVIDIA está disponível no repositório MLPerf, para que todos possam obter os mesmos resultados de classe mundial. A empresa incorporará continuamente as otimizações em contêineres disponíveis no hub de software NVIDIA NGC para aplicativos de GPU. Sobre a NVIDIA Desde sua fundação em 1993, a NVIDIA (NASDAQ: NVDA) tem sido pioneira em computação acelerada. A invenção da GPU pela empresa em 1999 estimulou o crescimento do mercado de games para PC, redefiniu a computação gráfica, iniciou a era da IA moderna e tem ajudado a digitalização industrial em todos os mercados. A NVIDIA agora é uma empresa de computação full-stack com soluções em escala de data center que estão revolucionando o setor. Mais informações em: https://blog.nvidia.com.br/. Acesse também: Site oficial da NVIDIA no Brasil: https://www.nvidia.com/pt-br/ Facebook: @NVIDIABrasil Twitter: @NVIDIABrasil YouTube: NVIDIA Latinoamérica Este conteúdo foi distribuído pela plataforma SALA DA NOTÍCIA e elaborado/criado pelo Assessor(a):
U | U
U





















 está com a")

